Info
ANN-Benchmarks is a benchmarking environment for approximate nearest neighbor algorithms search. This website contains the current benchmarking results. Please visit http://github.com/erikbern/ann-benchmarks/ to get an overview over evaluated data sets and algorithms. Make a pull request on Github to add your own code or improvements to the benchmarking system.
Benchmarking Results
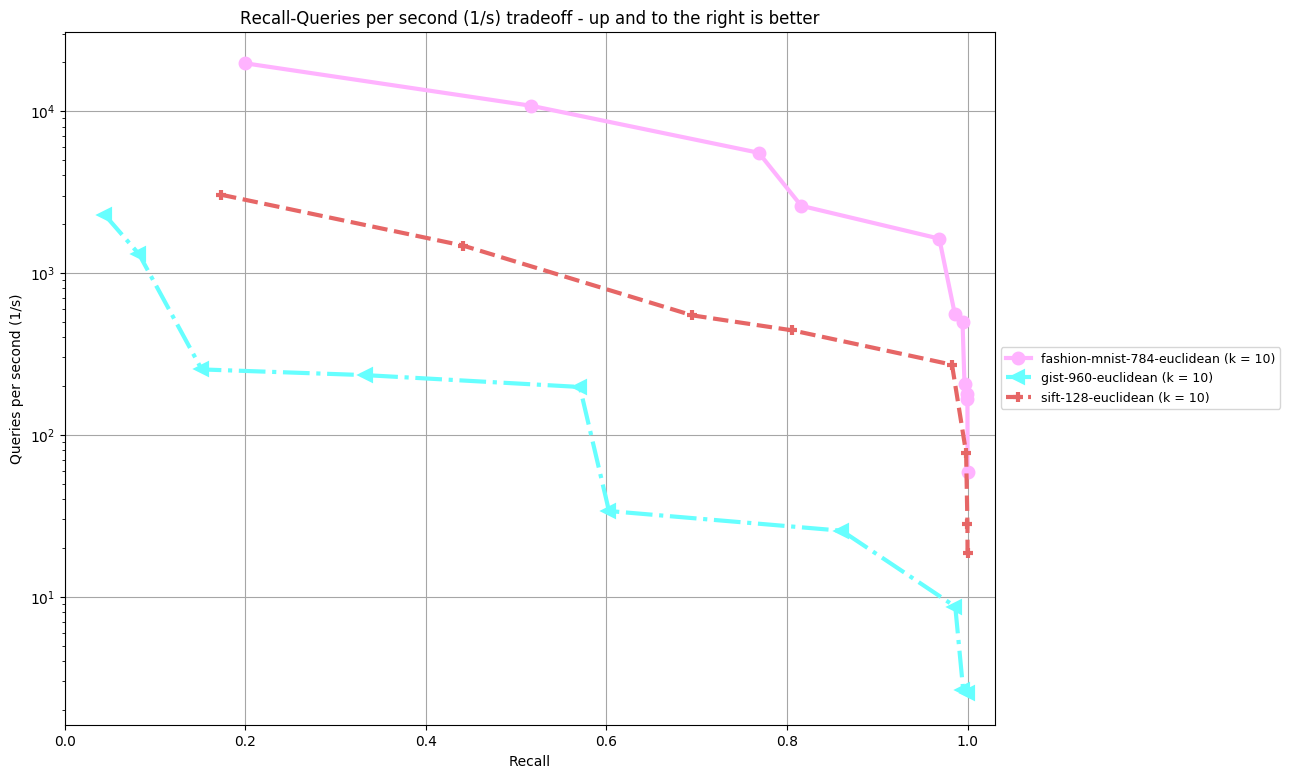
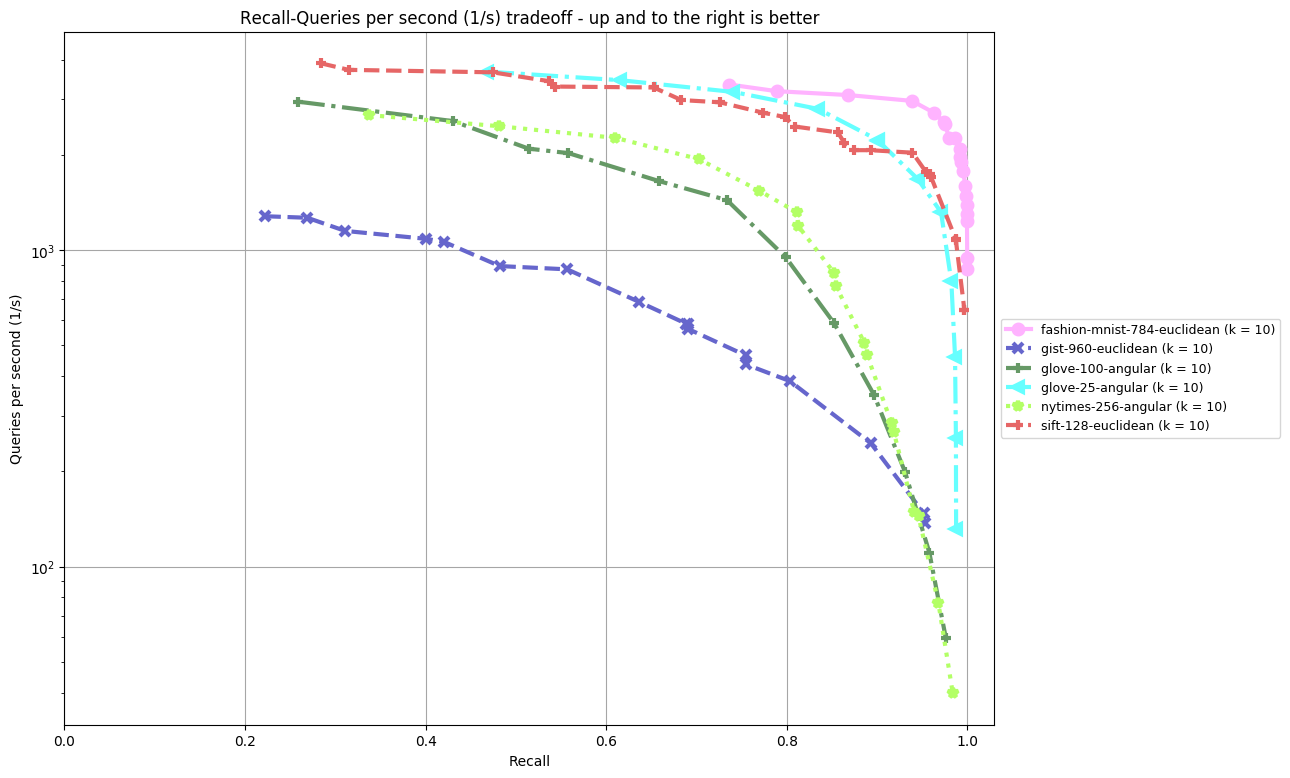
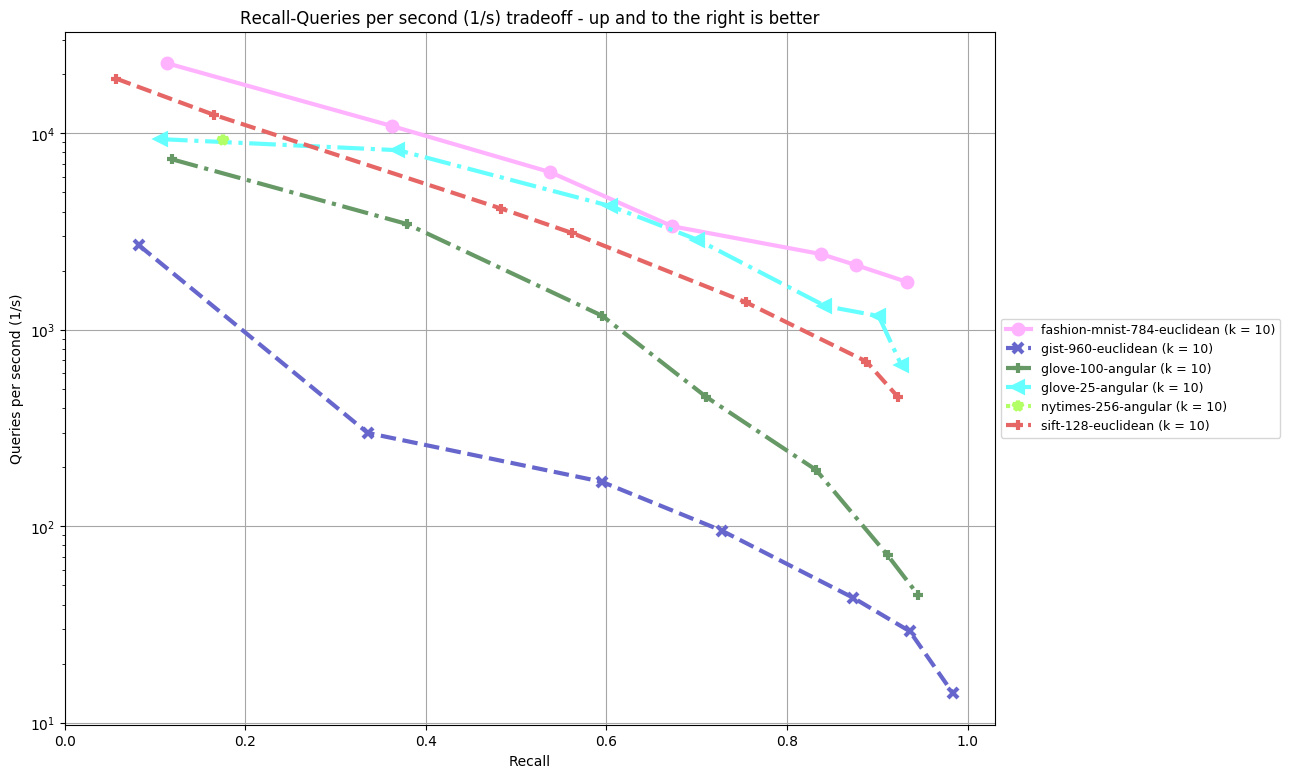
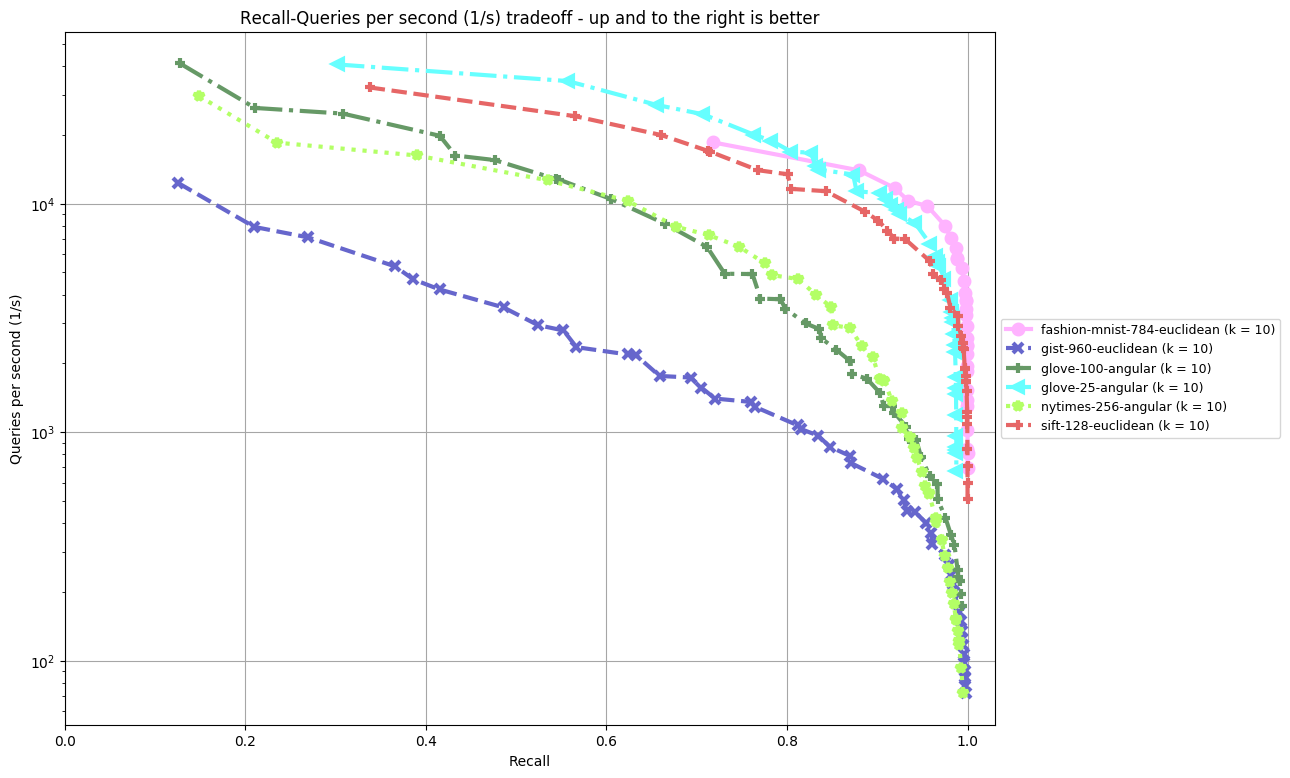
Results are split by distance measure and dataset. In the bottom, you can find an overview of an algorithm's performance on all datasets. Each dataset is annoted by (k = ...), the number of nearest neighbors an algorithm was supposed to return. The plot shown depicts Recall (the fraction of true nearest neighbors found, on average over all queries) against Queries per second. Clicking on a plot reveils detailled interactive plots, including approximate recall, index size, and build time.
Results by Dataset
Distance: Angular
glove-100-angular (k = 10)
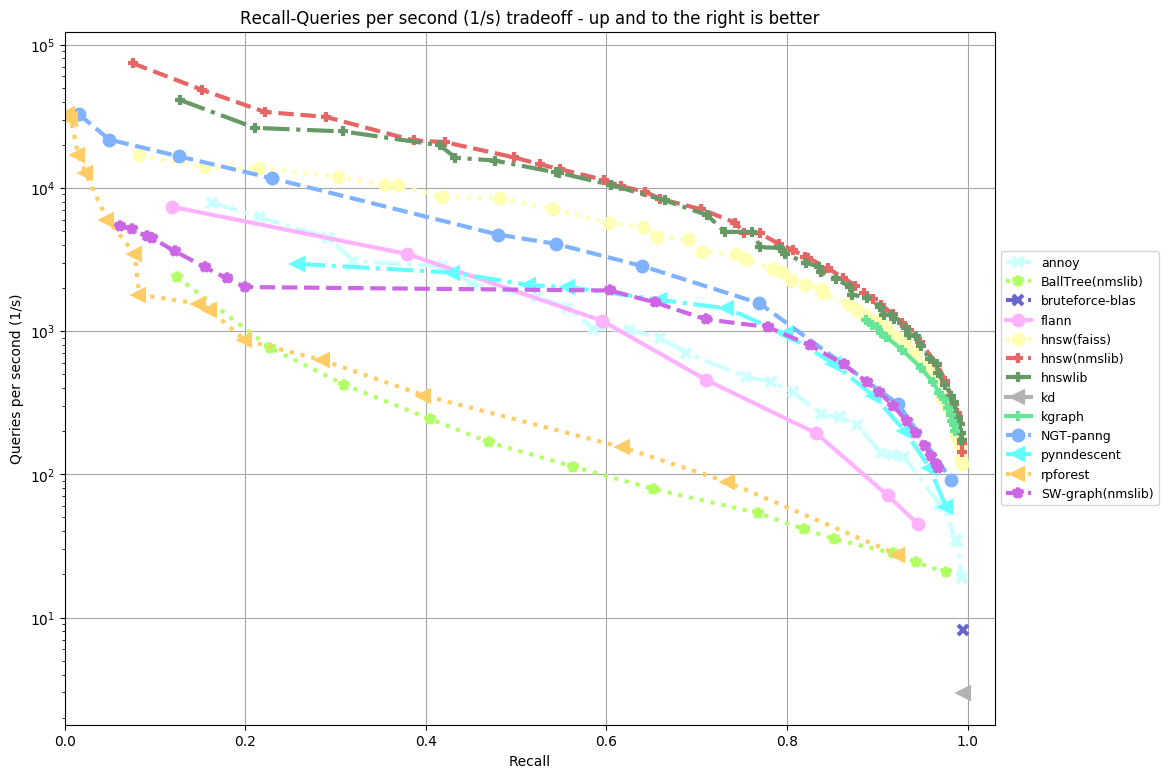
glove-25-angular (k = 10)
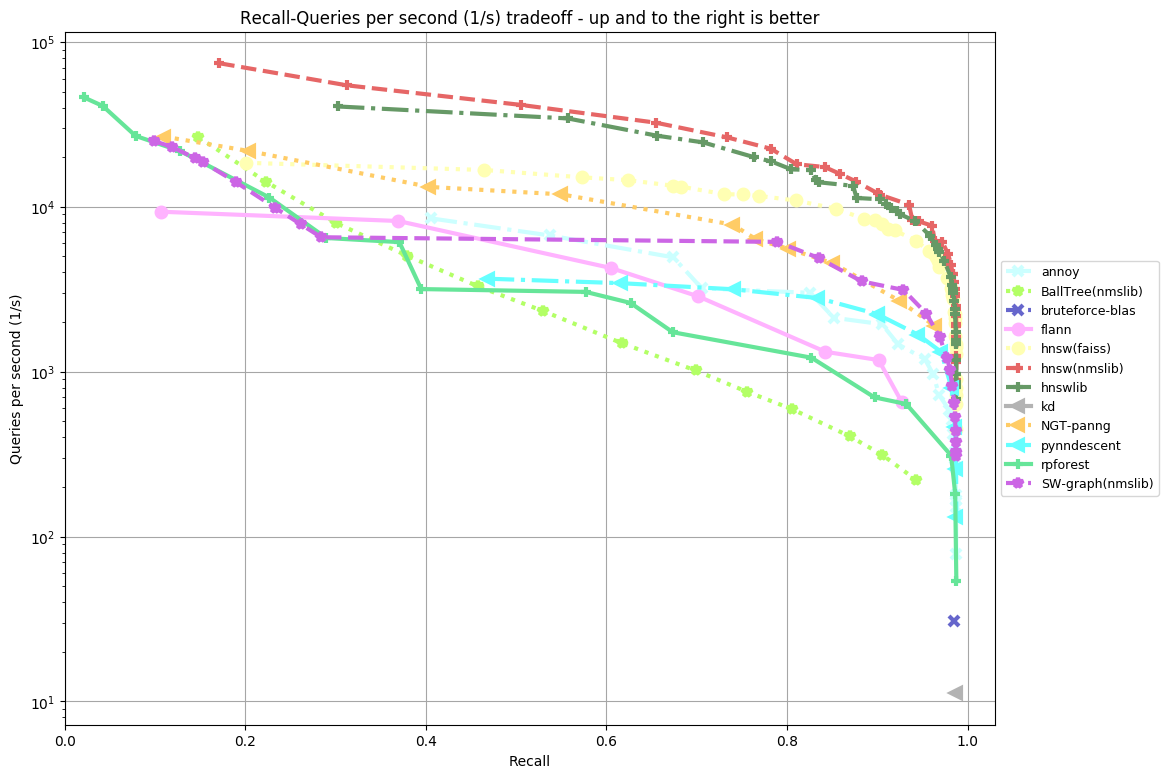
nytimes-256-angular (k = 10)
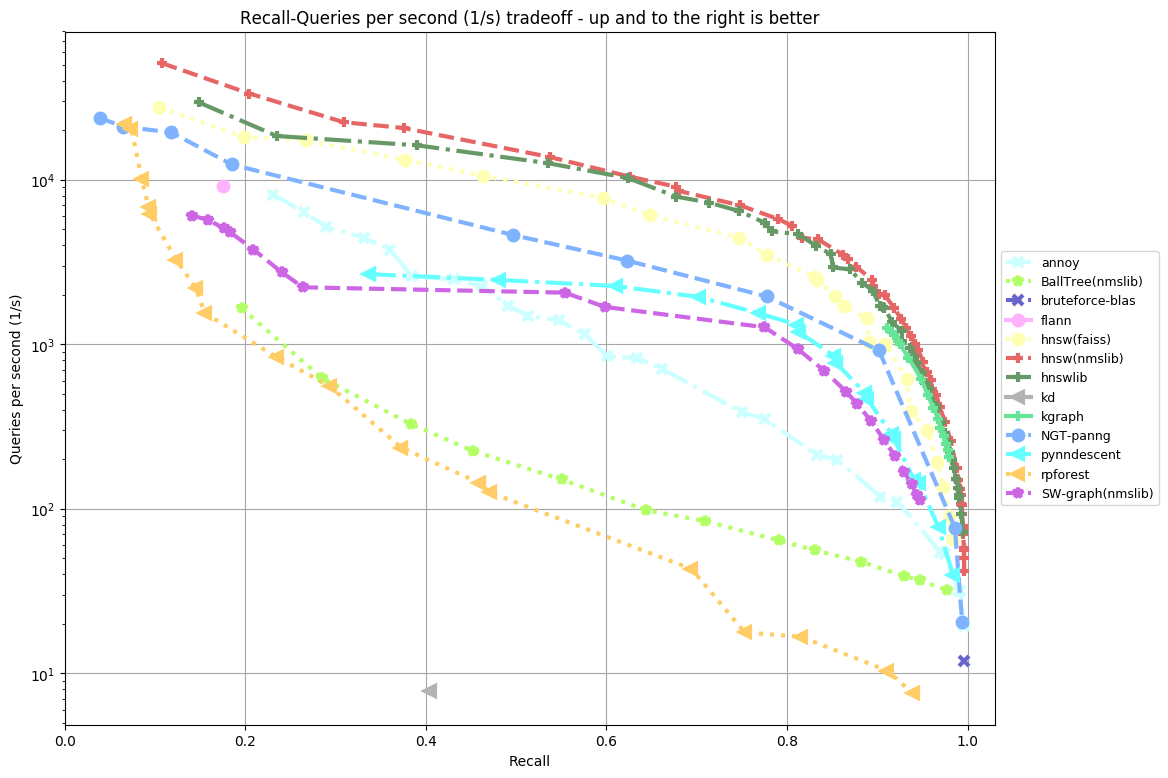
Distance: Euclidean
fashion-mnist-784-euclidean (k = 10)
gist-960-euclidean (k = 10)
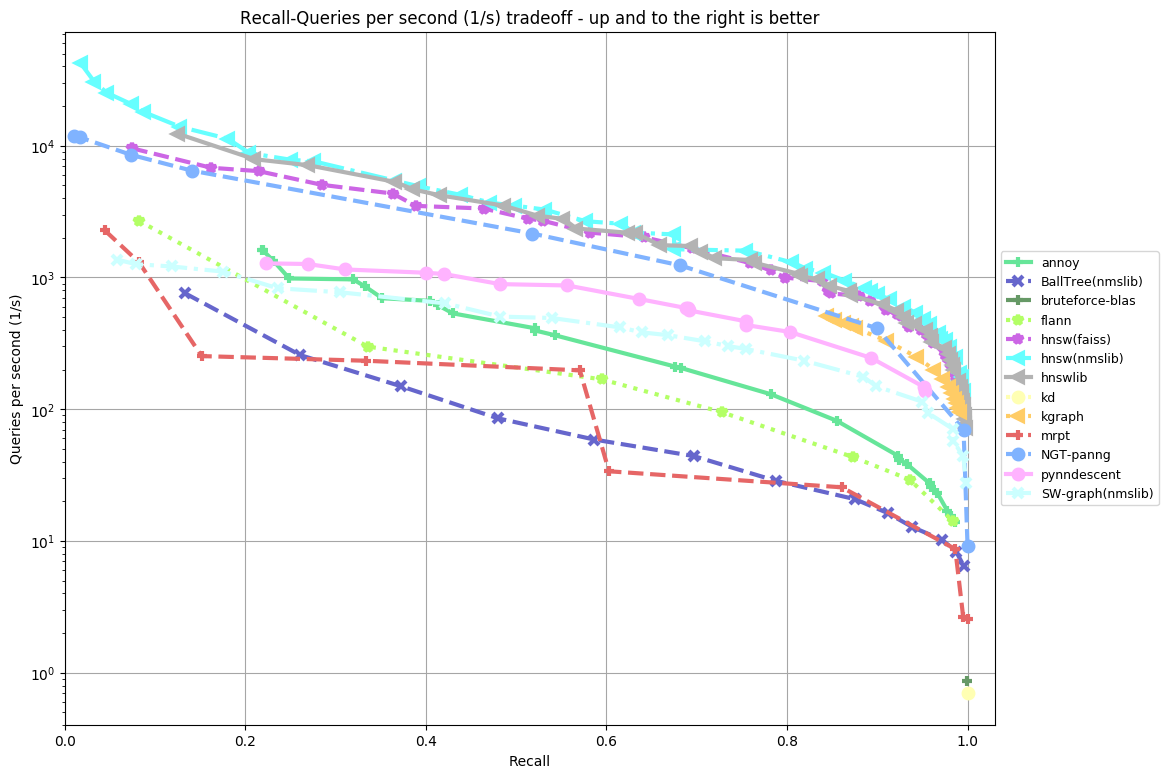
sift-128-euclidean (k = 10)
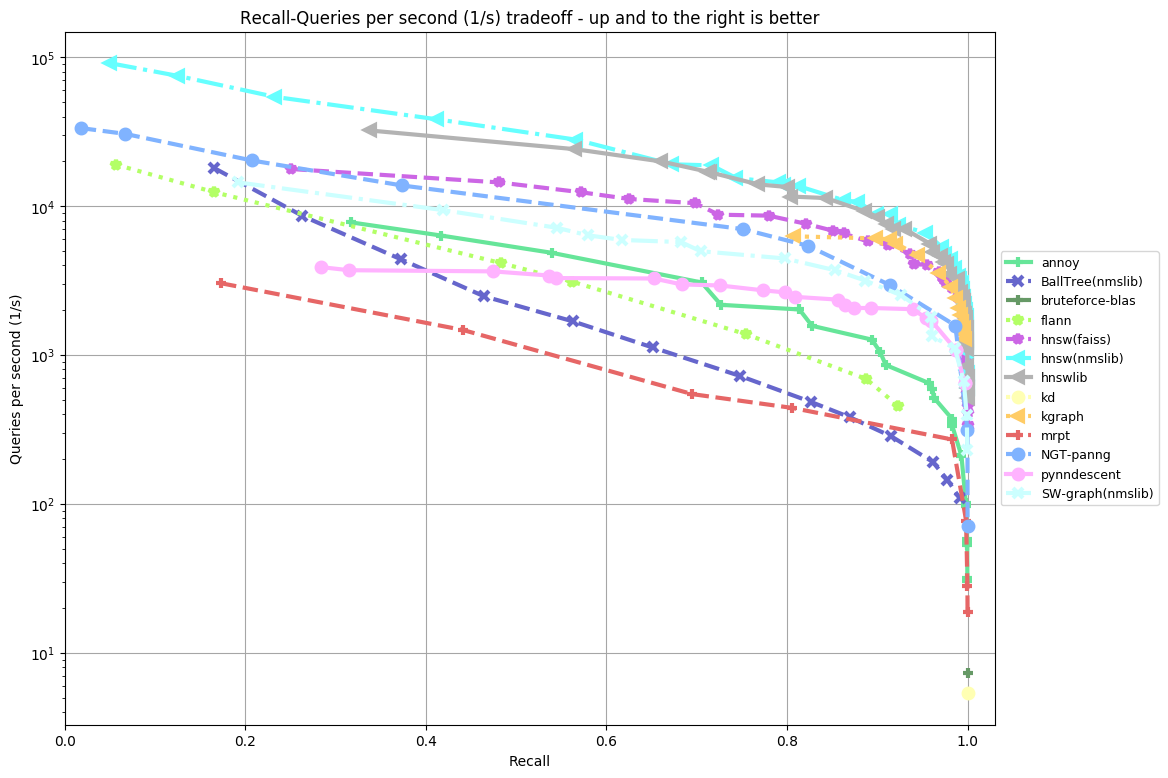
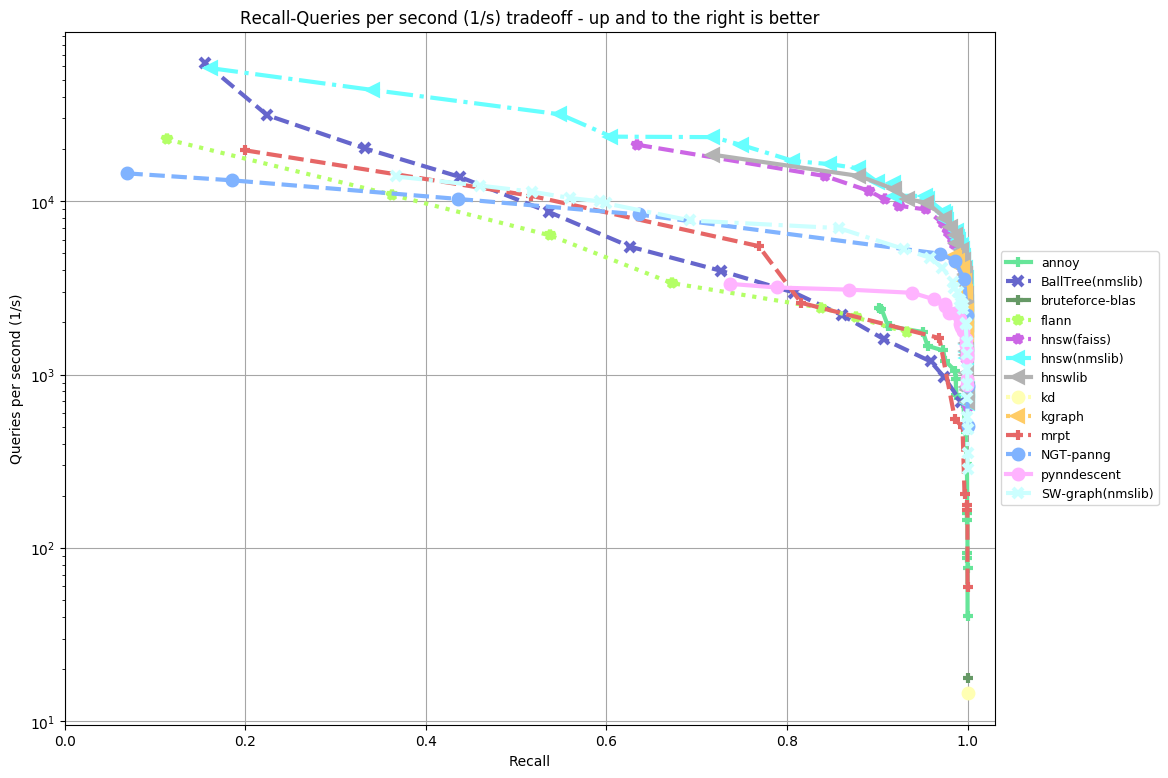
Results by Algorithm
- Algorithms:
- mrpt
- hnsw(nmslib)
- pynndescent
- flann
- BallTree(nmslib)
- bruteforce-blas
- hnswlib
- kd
- hnsw(faiss)
- SW-graph(nmslib)
- annoy
- kgraph
- rpforest
- NGT-panng
mrpt
hnsw(nmslib)
.png)
pynndescent
flann
BallTree(nmslib)
.png)
bruteforce-blas
hnswlib
kd
hnsw(faiss)
.png)
SW-graph(nmslib)
.png)
annoy
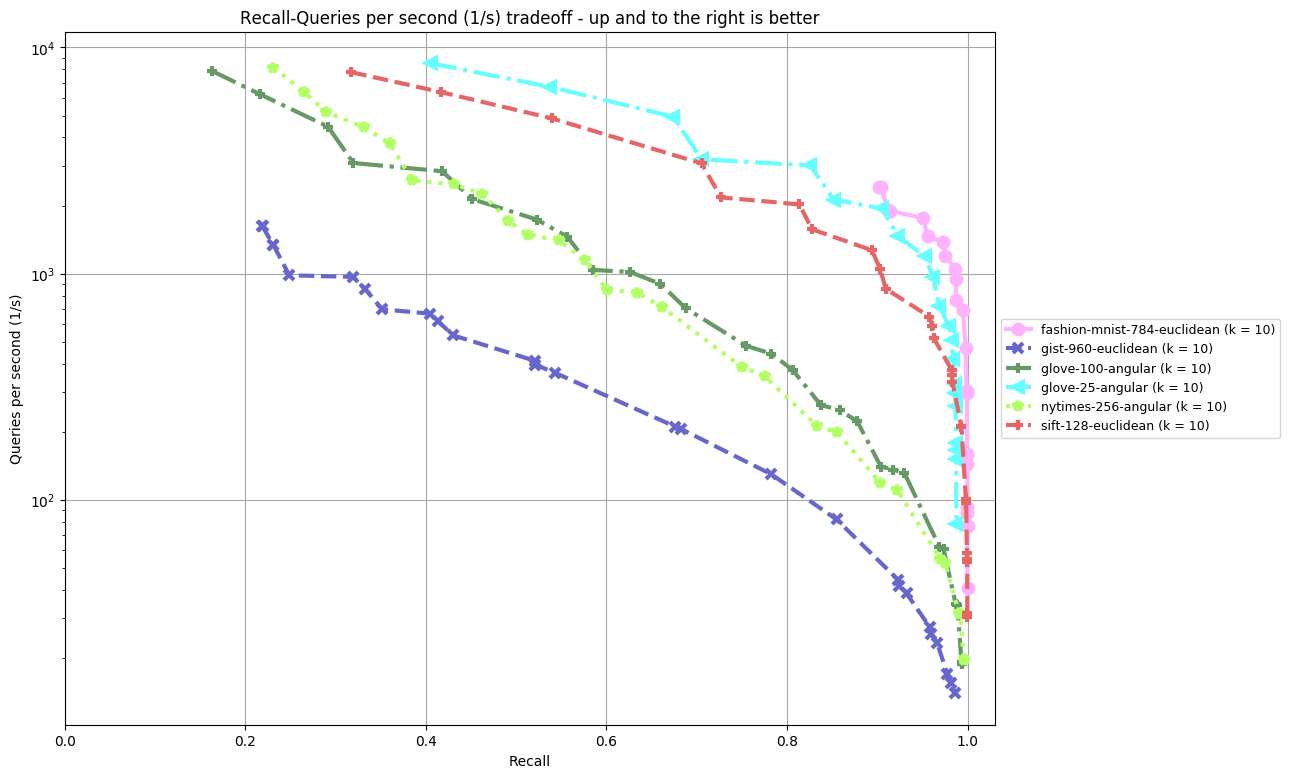
kgraph
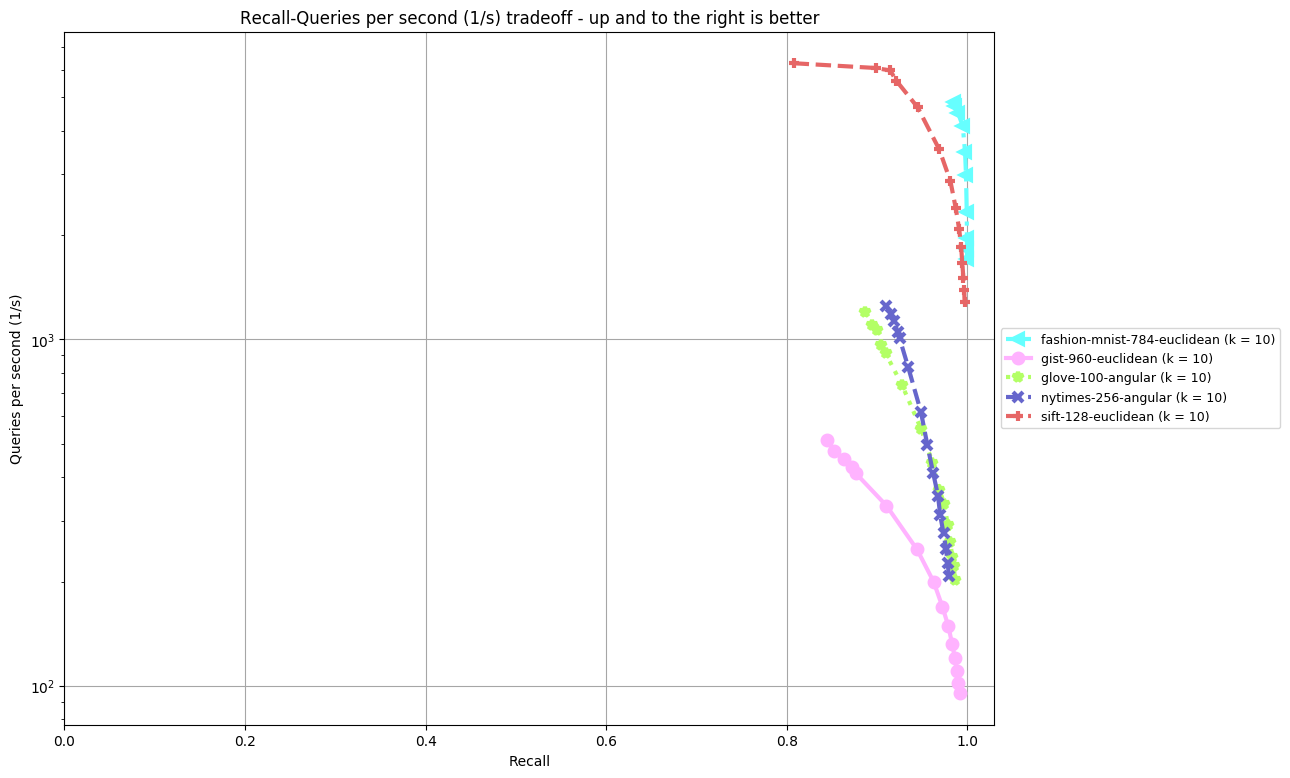
rpforest
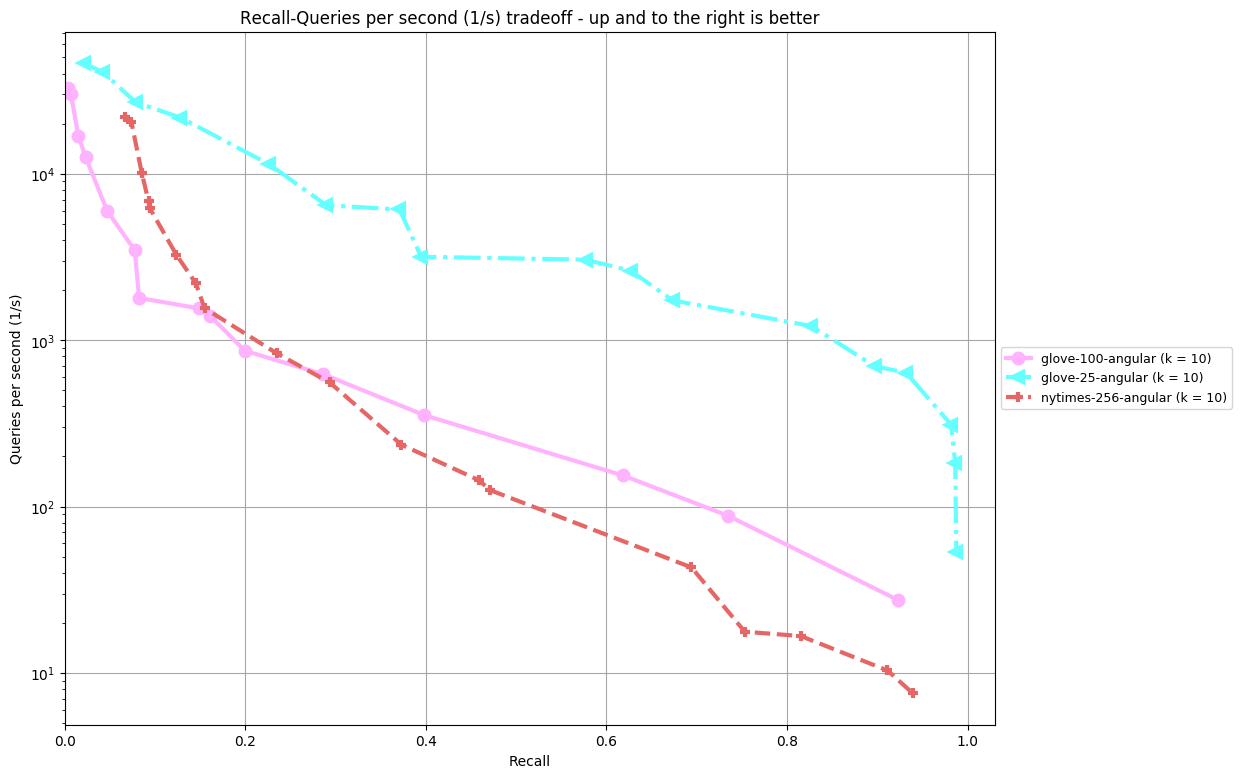
NGT-panng
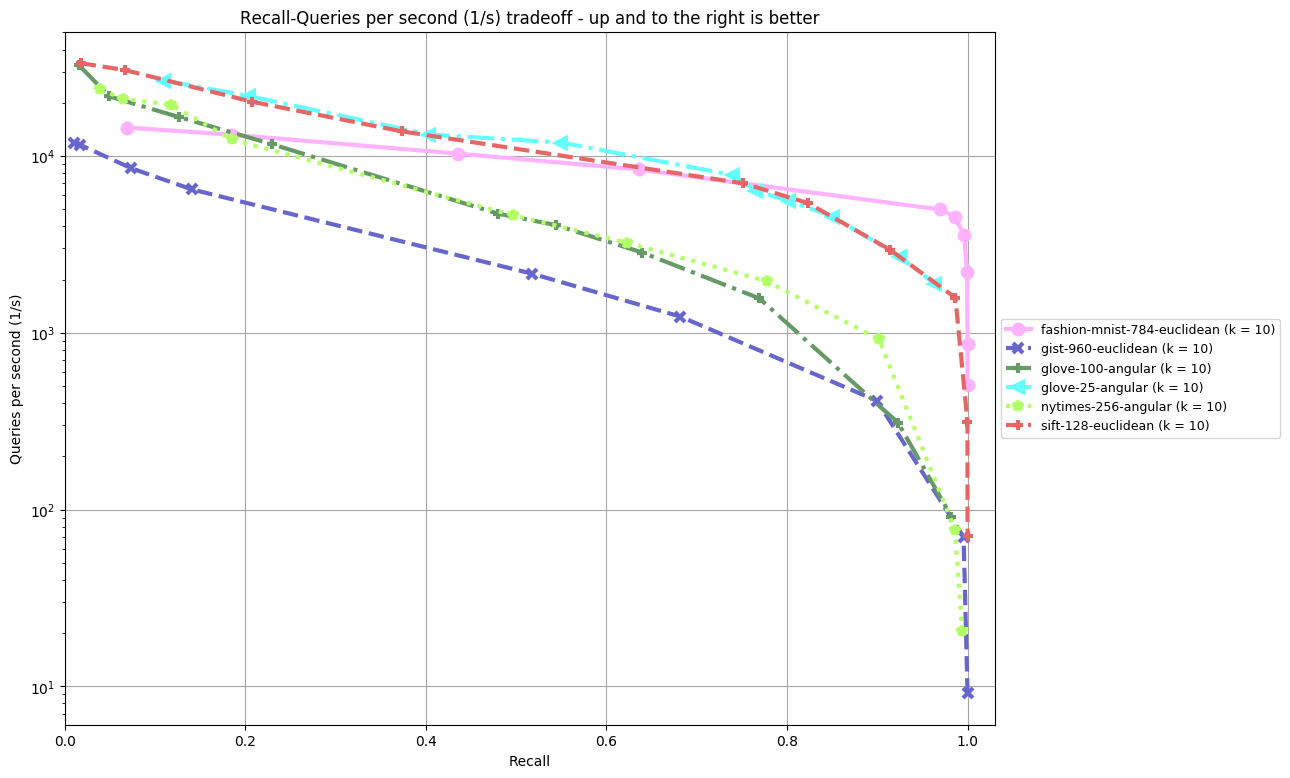
Contact
ANN-Benchmarks has been developed by Martin Aumueller (maau@itu.dk), Erik Bernhardsson (mail@erikbern.com), and Alec Faitfull (alef@itu.dk). Please use Github to submit your implementation or improvements.